Turn AI Agents intoProfitable Assets
Generic benchmarks don’t reflect your business reality. What matters is knowing exactly which tasks your agents can perform reliably , so you can delegate with confidence and measure ROI for evaluating, testing, and optimizing your AI agents with advanced capabilities.
Value
Proposition
Our SaaS platform goes beyond abstract scores. We evaluate your agents on detailed, organization-specific tasks the ones that actually drive value in your workflows. With clear insight into what works (and what doesn’t), you can act with certainty.
Control risk by spotting weak spots before they impact clients
Cut costs by delegating tasks you can trust 100%
Scale confidently by aligning AI to your business metrics
Control Risk
Identify failure modes and safety gaps with task-level evidence so issues get fixed before they touch clients.
Cut Costs
Delegate tasks you can trust 100%. Validate accuracy, reliability, and handoff criteria per workflow to reduce manual load.
Evidence over assumptions. Replace guesswork with measurable acceptance thresholds.
Scale with Confidence
Align AI performance to your business metrics not generic benchmarks so outcomes track to revenue, margin, and SLA goals.
Task-Level Clarity
Measure the exact tasks that matter to your org and turn results into decisions with transparent, reproducible evidence.
Profitable agents aren’t built on irrelevant benchmarks they’re built on evidence-based evaluation tied to your company’s bottom line.
See Norma in
Action
Watch how teams use Norma to build better AI experiences

Multi-Turn Scenarios
Build complex conversation flows that mirror real user interactions with your AI agents.
Detailed Analytics
Get comprehensive insights with LLM-powered scoring and actionable feedback for improvement.
CI/CD Ready
Seamlessly integrate with your development workflow for continuous quality assurance.
Built for AI
Excellence
Everything you need to ensure your AI agents deliver consistent, reliable performance in production environments
Extraction
We extract the most relevant data from user interactions and system outputs, enabling precise evaluation of key data points in multi-agent workflows.
Classification
We assess classification tasks both as final outputs and as intermediary steps such as intent recognition or Guardrail activations to ensure agent behavior aligns with expectations.
Generation
We use LLMs to generate insights, justifications, and scores, enabling detection of hallucinations and assessment of output quality in generated text.
Built in the Open,
For Builders Everywhere
LevelApp is an open framework for evaluating AI assistants configuration to insights with community-driven features, transparent development, and an MIT license.
pip install levelapp




Joined by a growing community of contributors.
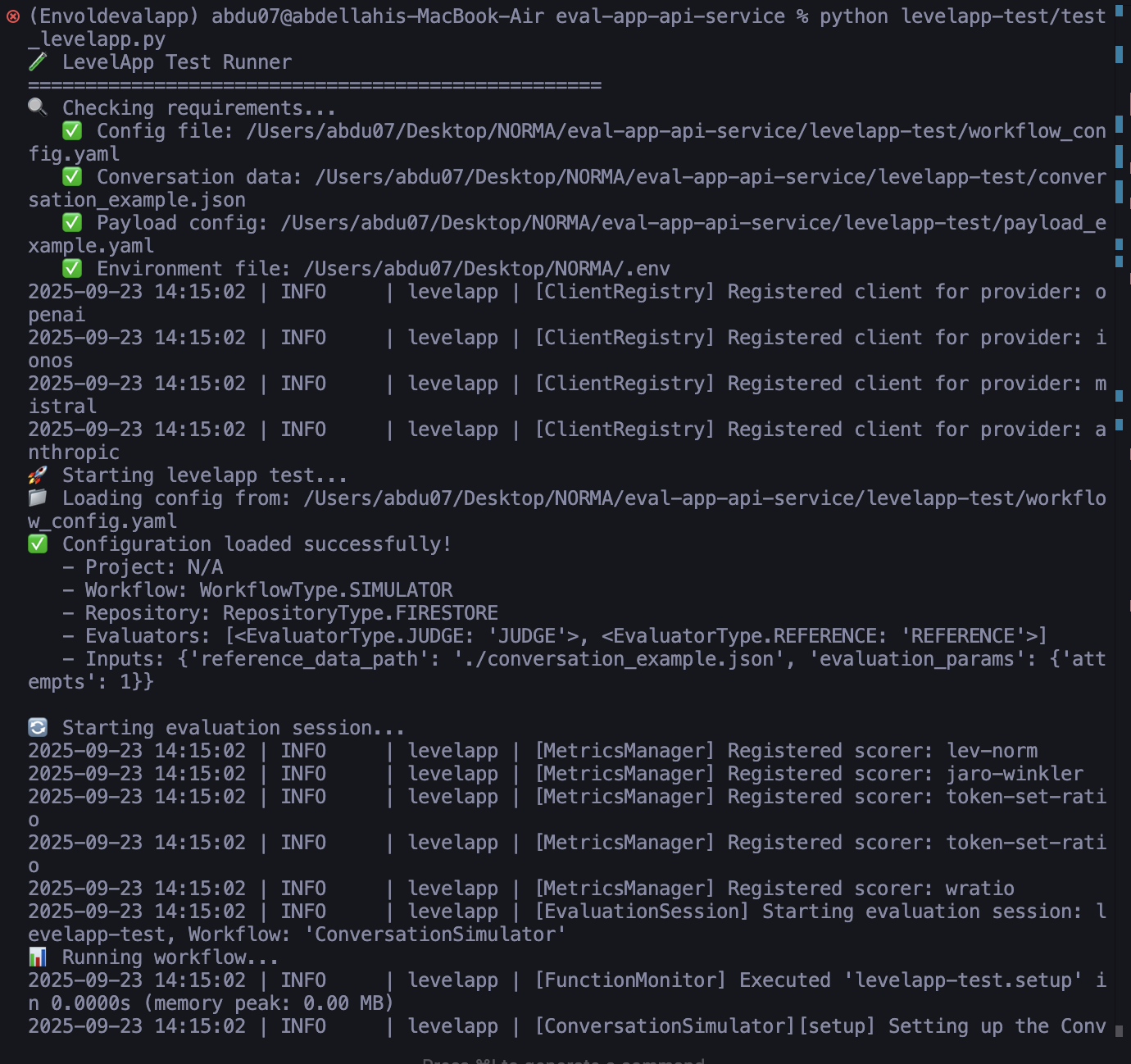
Explore the code, open issues, and roadmap on GitHub. Your feedback and PRs are welcome.
Complete Evaluation
Workflow
From configuration to insights, see how Norma streamlines your AI evaluation process
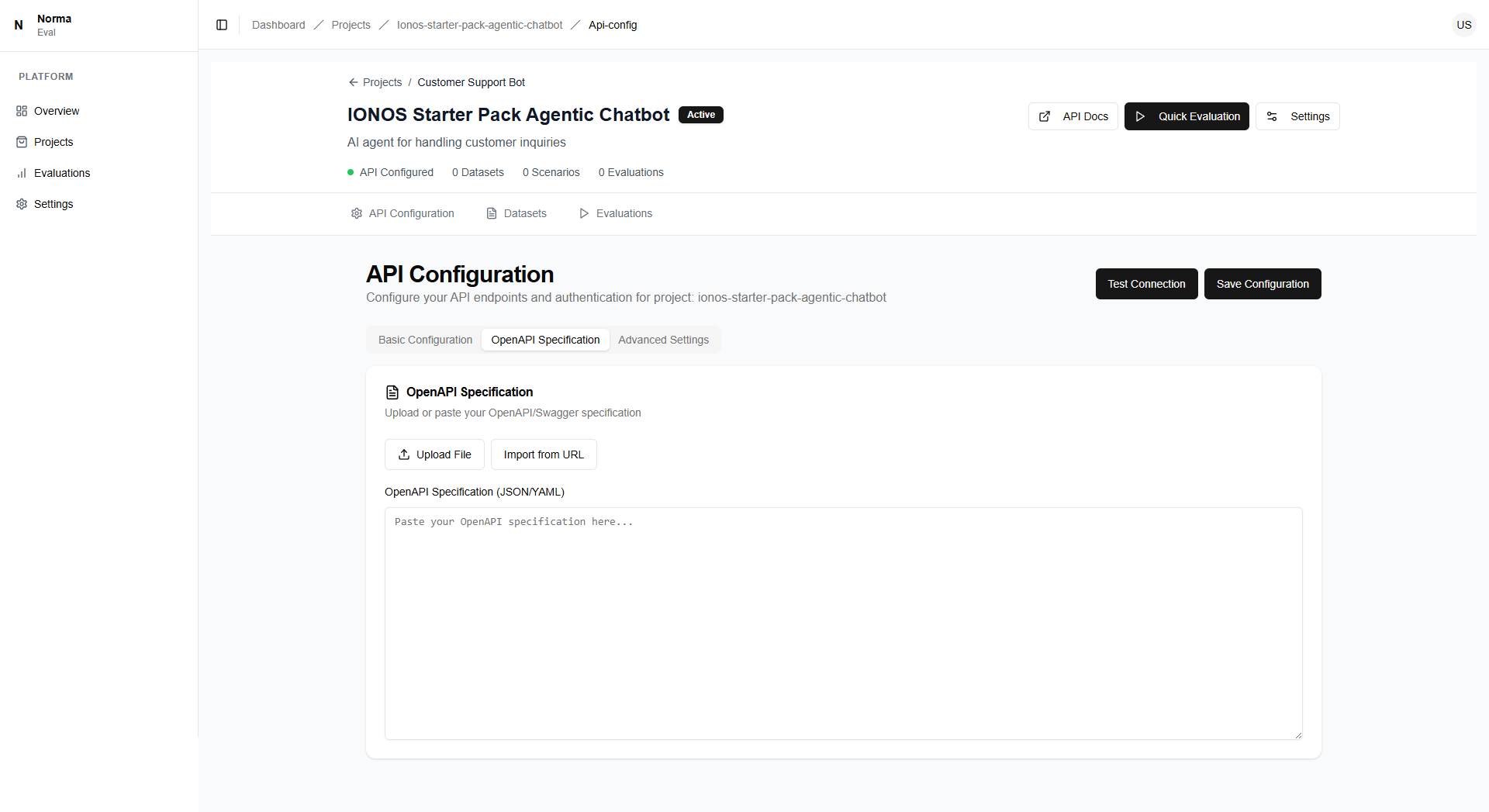
Configure & Connect
Set up your API endpoints and authentication in minutes
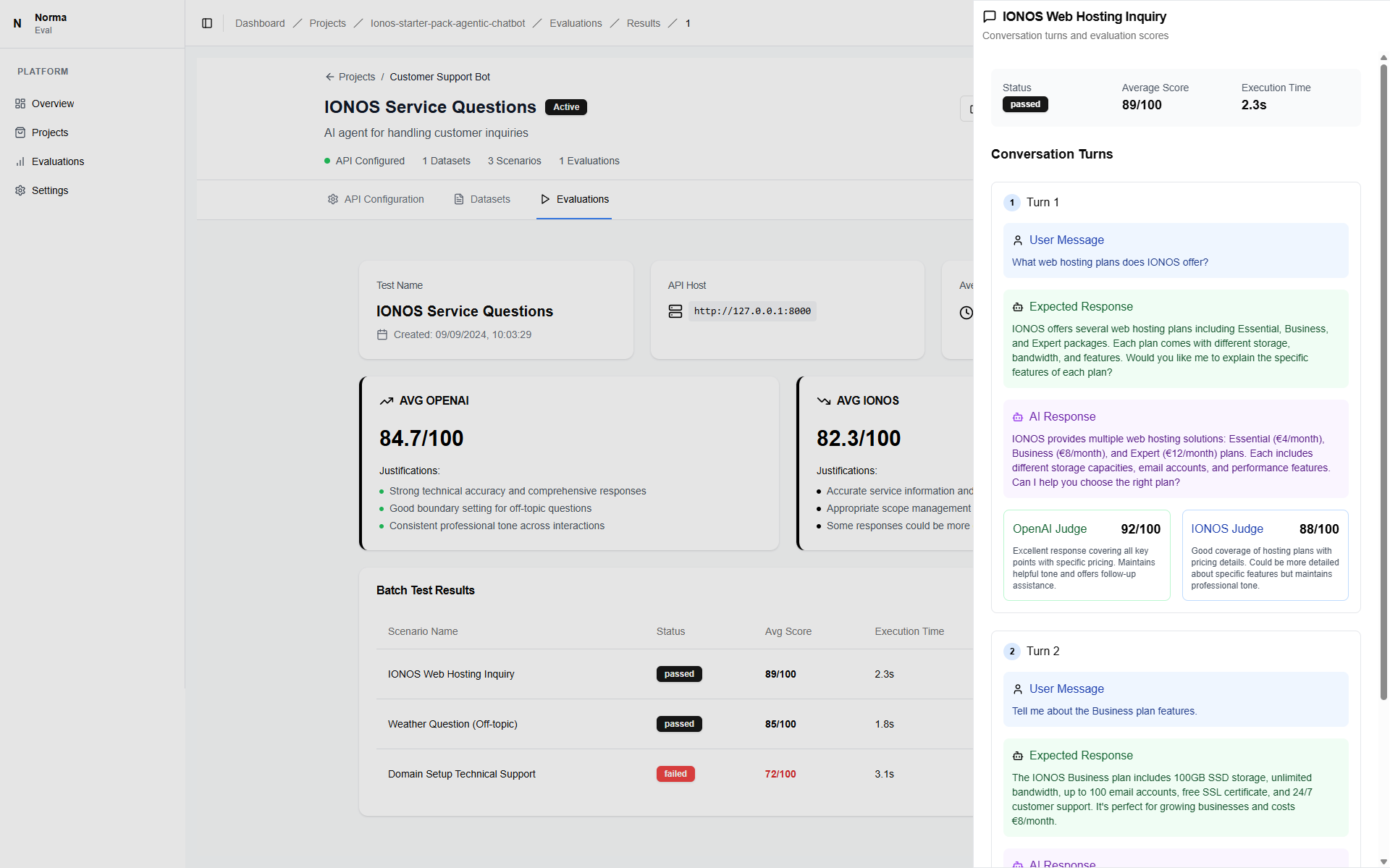
Analyze & Optimize
Get detailed insights and actionable feedback from LLM judges
Ready to Elevate Your
AI Agents?
Join hundreds of teams already using Norma to build better AI experiences. We’re actively seeking partners, SaaS clients, and open-source contributors.
Partners
Strategic partnerships for mutual growth
SaaS Clients
Enterprise solutions for AI evaluation
Contributors
Open-source community collaboration
Be the First to Try
LevelApp SaaS
We’re opening early access to a limited number of teams. Get priority access, exclusive testing perks, and direct influence on the roadmap.